PatchTST笔记
引言
时间序列预测在许多实际应用中具有重要意义,如能源预测、交通流量预测、气象预测等。随着深度学习技术的进步,基于Transformer的模型在时间序列预测中表现出了强大的能力。然而,传统Transformer模型存在计算复杂度高、内存消耗大等问题,尤其在长序列预测中效果不佳。PatchTST模型通过创新性的设计,解决了这些问题,提出了分块(Patching)和通道独立性(Channel-independence)的解决方案,显著提高了时间序列预测的效率和精度。
模型
Tip
表示学习(Representation Learning),也常被称为特征学习(Feature Learning),是指让模型自动地从原始数据中发现和提取“特征”或“表示”的技术,而不是依靠人工手动设计规则 。
可以暂且认为,表示学习可分为以下三种:
- 有监督表示学习:在学习特征的同时,利用标签(如未来的真实值)来纠正模型,让特征直接服务于特定目标 。
- 自监督表示学习:不利用标签,通过数据自身的结构(如掩码 Patch)来学习特征 。这是本文的核心亮点。
- 迁移学习(Transfer Learning):在数据集 A 上学到的表示能力,直接应用到数据集 B 上 。
有监督学习
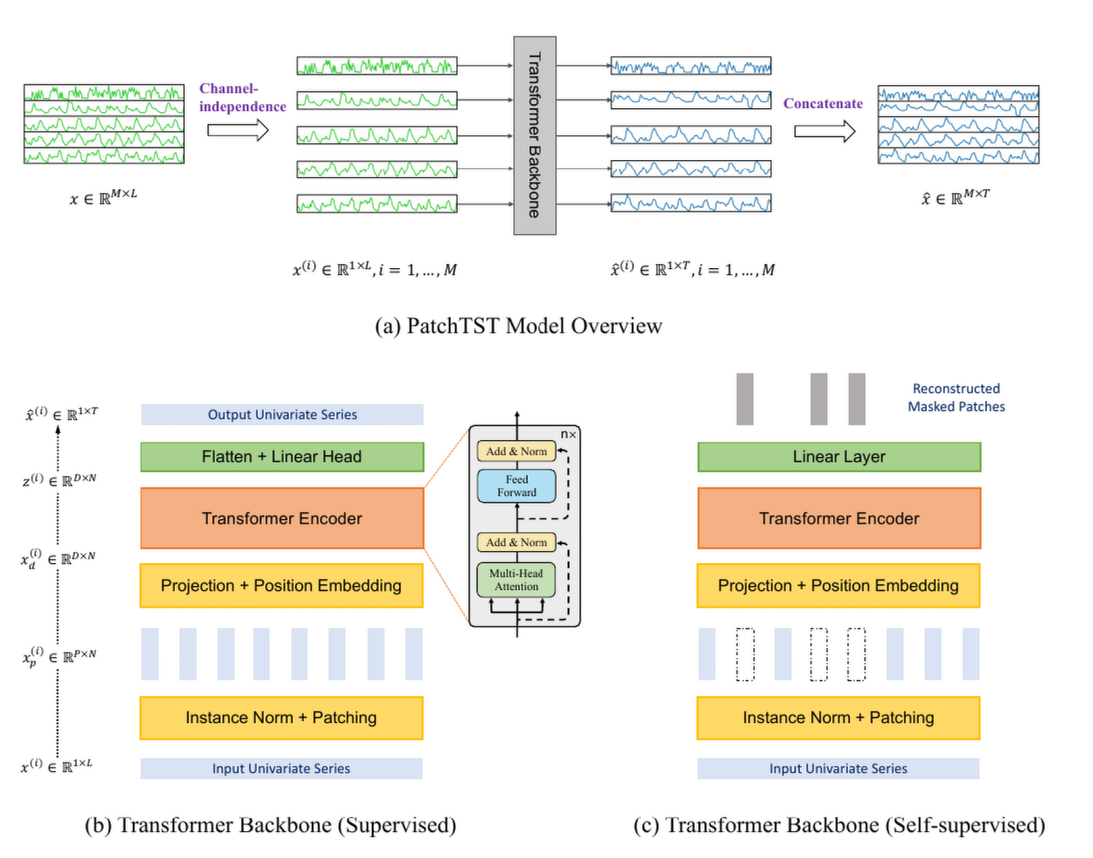
Channel Independent
作者强调,每个时间序列都将拥有自己的潜在表示,这些表示通过共享权重机制进行交叉学习 。这种设计允许预训练数据包含与下游数据不同数量的时间序列,这在其他方法中可能是不可行的 。
- 这种机制直接把channel维度和batch合并,也就是
[B, T, N] -> [B * N, T, 1] -> [B * N, T, d_model],这是后面被广泛遵循的处理方式。- 正是这样的设置,统一了模型处理的数据的第三维的形状,从而能够实现上文所说预训练和下游数据可以有“不同数量”(也就是原始通道维范围可以不同)
- “潜在表示”:指映射到
d_model维度上;- “共享权重”:指几个通道合并到
Batch维度一起送进模型,从而可以说共享模型的权重。
Instance Norm
每个子序列块会先经过标准化处理,使其均值为0,标准差为1,从而减少不同序列之间的分布差异,避免训练过程中可能出现的梯度消失问题;输出预测的时候我们再加回均值和偏差。
其中 和 分别是子序列块 的均值和标准差。
Patching Design
在PatchTST中,时间序列首先被切分成多个子序列块(patches)。每个子序列块代表时间序列中的一段连续区间,而不是直接将单个时间步作为输入。假设每个时间序列的长度为 ,我们将其切分为长度为 的子序列,并根据设定的步长(stride) 决定每个块之间的重叠程度,得到 个子序列块。
Note
这里在分块前,向原始序列末尾填充了 个重复的末位值 。
这样分块相比传统的Transformer,有以下优势:
- 保留局部语义:单个时间步缺乏语义意义,而通过聚合时间步,可以捕捉更全面的局部语义信息 。
- 降低计算复杂度:将输入序列长度 降低为 ( 为步长),使得注意力图的计算和内存使用呈二次方级减少 。
- 支持更长历史:由于计算量的降低,模型可以处理更长的Look-back window,从而提取更多信息 。
Transformer Encoder
我们使用原生的 Transformer 编码器将观测信号映射到潜在表示(latent representations)。每个分块后的时间序列子序列会经过以下步骤进行嵌入:
- 实例标准化(Instance Normalization):前面已经说过详细方法;
- 编码:
- 每个子序列块先经过一个线性投影 被映射到维度为 的 Transformer 潜在空间;
- 添加可学习的位置编码,确保模型能够识别时间序列中各个时间步的位置;
- ,其中 表示将输入到 Transformer 编码器的数据。
- 多头注意力中的每个头 将其转换为查询矩阵 、键矩阵 和值矩阵 ;
- 使用缩放点积来获取注意力输出
- 其他设定如展平层等可以看结构图,和传统Transformer类似。

自监督学习
- 经典的时序模型都是采用Supervised Learning范式来进行预测,也就是未来的真实数据其实就是标签,模型将预测的未来数据和真实值对比,计算误差(如MSE)从而确定优化方向。
- 而这节的大意是,
PatchTST可以先进行一种自监督预训练,然后一些迁移到小数据量的任务上来fine tuning(通常这个阶段也被称为所谓 “下游”),效果也很好,这是由它的design决定的。- 所谓迁移学习,就是预训练+在下游其他任务上微调。
自监督学习
- 自监督学习是一种机器学习范式。它的核心思想是:从数据本身挖掘“标签”来作为监督信号。
- 有监督学习需要人类手动打标签,比如给出序列的真实值;
- 自监督学习通过mask autoencoder来实现:随机隐藏一部分输入序列的数据,让模型预测被隐藏的部分。
为什么模型也适合自监督?
- 本模型实现自监督学习,就是通过随机mask掉一部分patch(设置为0),然后根据MSE Loss(MSE是本模型指定的Loss Metric)训练,来重建这些patch。
- 如果不用patching,则每次mask只是以时间点为单位,这是有弊端的,具体如下:
- 这些时间点可以通过前后的值轻松地插值补全,而不需要学习全局特征,从而可能无法对整体序列有什么理解。
- 计算效率低;
- 用于预测任务的输出层设计可能会很麻烦 。如果预测头需要处理过大的参数矩阵,可能会在下游训练样本稀缺时导致过拟合 。
Tip

参数大,所以就会学习到太详细的噪声,从而导致过拟合。原文叙述如下:

自监督训练的架构改动
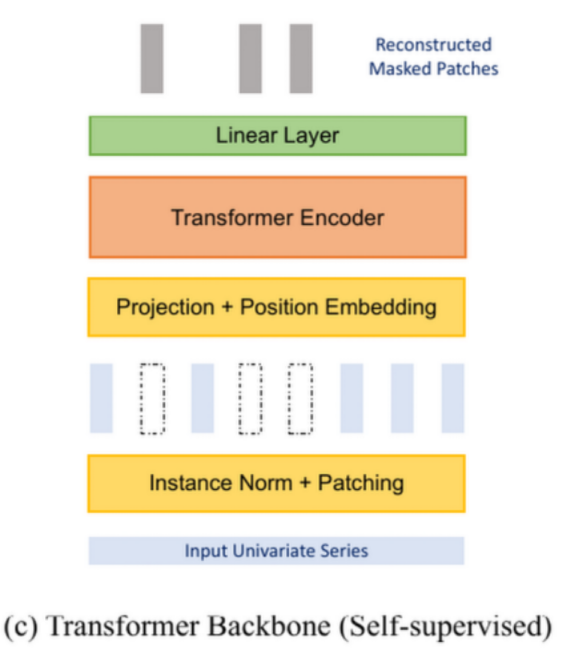
- 预测头被移除,变成一个 的线性层,通过这个先行层;
- 每个输入序列必须被划分为规则的非重叠块(patch),否则被mask掉的块的信息会在已知块中泄露。
- mask的流程是在编码之前做的,是对mask之后的原始序列编码,而被mask块的位置编码仍然会被保留,这也是模型能够还原被mask块的关键!
自监督方式预测的实验流程
- 自监督训练100轮,获得预训练模型;
- 在下游进行有监督训练,有两种训练方法:
- Linear Probing:只训练模型的线性预测头,其他部分冻结,训练20轮;
- End-to-end Fine Tuning:先训练10轮的线性预测头,其他部分冻结(预热);然后解冻网络其他部分,整体fine-tuning,这一阶段进行20轮。
论文的实验证明第二种方法比单纯的linear probing效果好。
自监督方法对比实验
- 自监督学习有两个大的派系:
- 生成/重构式自监督(Generative/Reconstructive SSL):代表作是 Masked Autoencoders (MAE)。PatchTST 采用的就是这种方法——遮住一部分数据,让模型“重构”出来 。
- 对比式自监督(Contrastive SSL):通过让模型区分“相似”和“不相似”的样本来学习特征 。论文中提到的 BTSF、TS2Vec、TNC、TS-TCC 都是这种“对比学习派系”的代表 。
对比学习(Contrastive Learning) 实际上是自监督学习的一个子集,它的主要思想是让模型自己学习区分出正样本(相似的样本)和负样本(不相似的样本),从而获取数据的高阶特征表示;它要求模型在特征空间中能够缩短正样本对之间的距离(Pull),而拉大负样本对之间的距离(Push)。
Important
如果有时间,应该系统了解一下对比学习,读一下这里提到的几种对比式自监督方法。
- 作者列出一些时序中较为先进的对比学习表示方法,然后将上述这个自监督方法和以上这些对比学习式自监督方法进行效果比较,证明了本文提出的路径更有效。
实验数据
有监督学习下与其他时序模型的对比
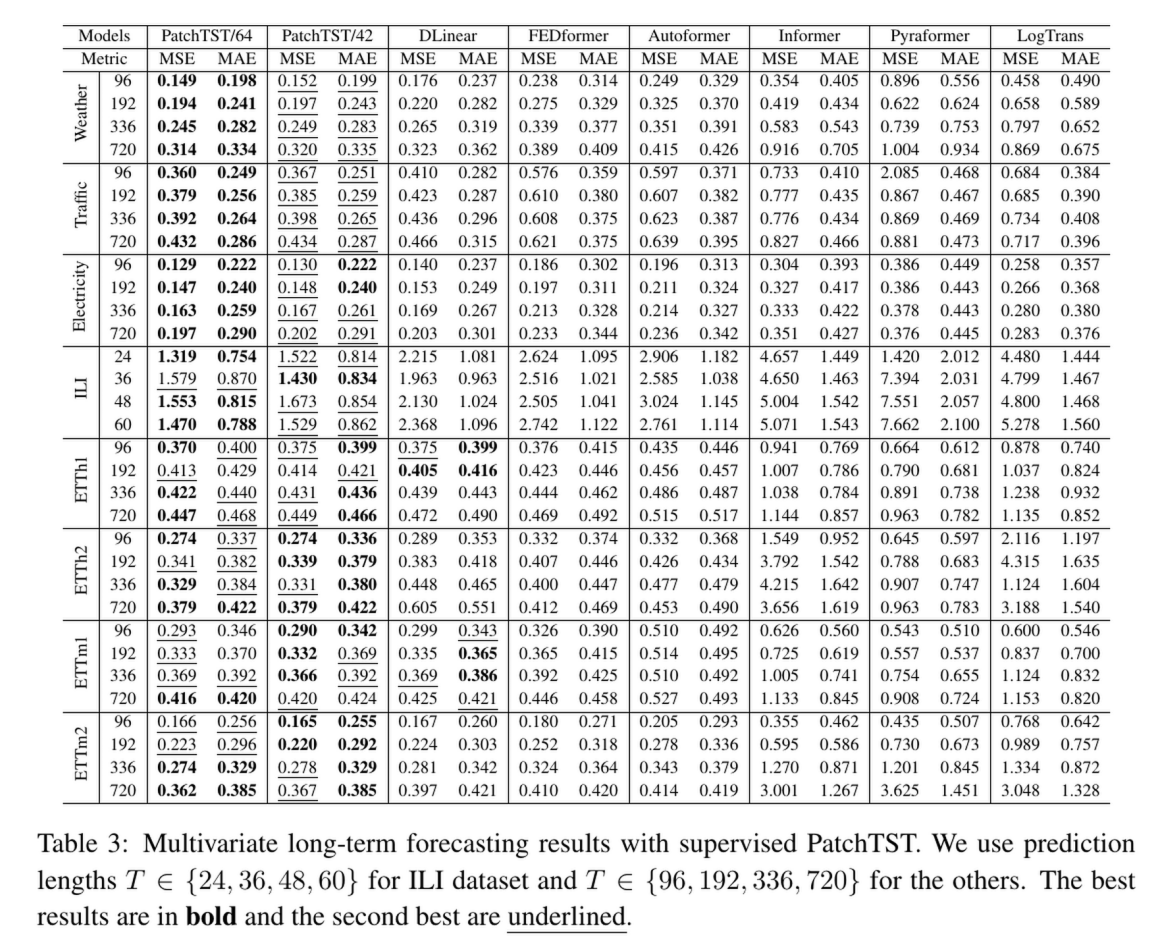
模型变体 (Model Variants)。 我们在表 3 中提出了 PatchTST 的两个版本 。PatchTST/64 意味着输入块的数量为 64,使用了 的回溯窗口 。PatchTST/42 意味着输入块的数量为 42,使用了默认的 回溯窗口 。两者都使用块长度 和步长 。因此,我们可以使用 PatchTST/42 作为与 DLinear 和其他基于 Transformer 模型的公平比较,并使用 PatchTST/64 在更大的数据集上探索更好的结果 。更多实验细节在附录 A.1 中提供 。
自监督学习下与其他时序模型的对比
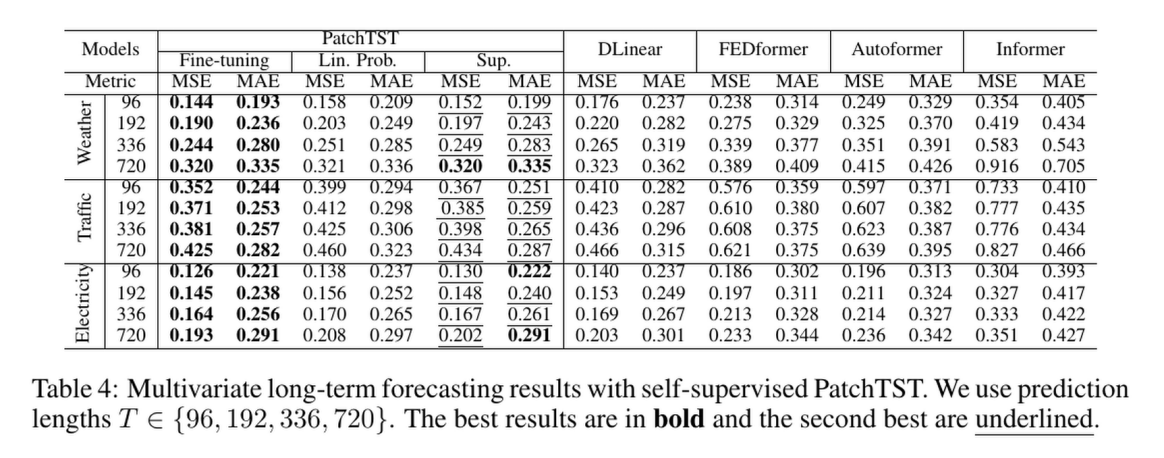
这里都用了42个输入块的数据做对比,也就是
seq_len = 336。
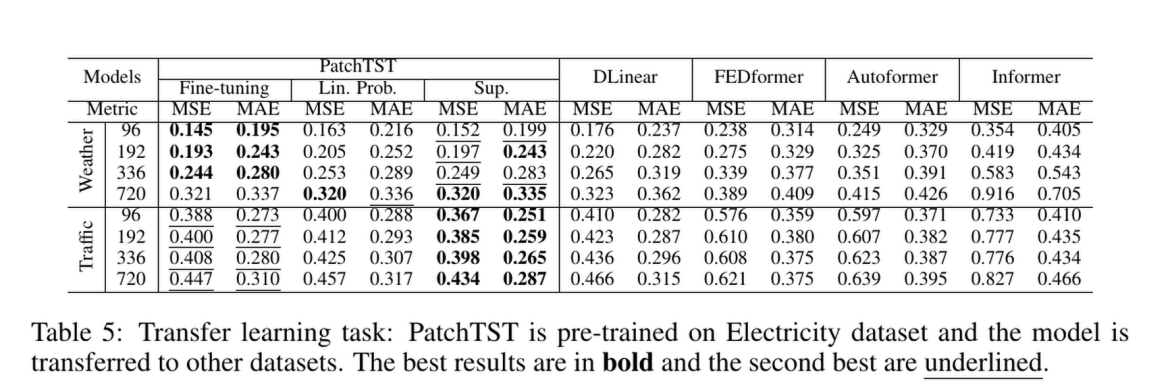
迁移学习有效性
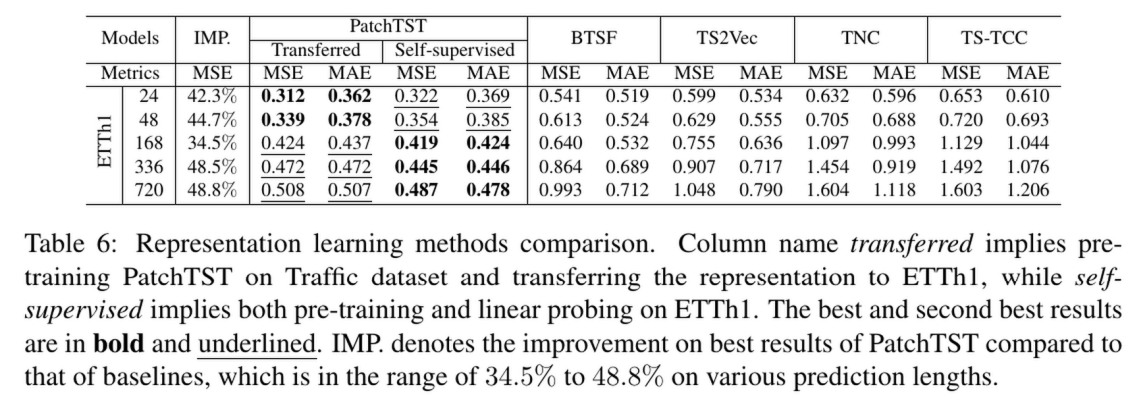
表示学习方法对比
总结
- 本文引入两个核心组件:分块(patching) 和 通道独立(channel-independent) 结构,提出了一种针对时间序列预测任务的有效 Transformer 模型设计。
- 与以往的工作相比,该模型能够捕捉局部语义信息,并从更长的回溯窗口中获益 。模型不仅在有监督学习中优于其他基准模型,在自监督表示学习和迁移学习方面也具有足够的潜力 。
- 模型展现出成为未来 Transformer 预测工作基础模型的潜力,并可作为时间序列基础模型的一个构建块。分块设计虽然简单,但已被证明是一个有效的算子,可以轻松迁移到其他模型中 。
- 另一方面,通道独立设计可以被进一步挖掘,以整合不同通道之间的相关性 。妥善建模跨通道依赖性将是未来的一个重要步骤 。
Note
模型关于通道独立的归纳偏置比较武断,所以就像论文总结所说的一样,探寻通道之间的依赖性也是很重要的事情怎么定义相关性,怎么发掘相关性,怎么利用相关性处理,都是问题。